
Pomocí AI měníme firemní data v konkurenční výhodu
Jsme konzultační a implementační firma pro enterprise AI a data. Od roku 2016 poskytujeme end-to-end AI a datová řešení, od AI strategie, přes pilot až po škálování.
















.avif)

AI řešení na míru
Hledáte vlastní řešení AI? Poskytujeme komplexní služby s odbornými znalostmi v aplikované umělé inteligenci, včetně funkcí Gen AI, jako jsou znalostní báze a asistenti. Naši odborníci se také specializují na strojové učení pro předpovídání poptávky, křížový prodej/upselling atd.
AI strategie a konzultace
BigHub vaší firmě pomůže odemknout potenciál umělé inteligence, a to identifikací ideálního použití, posouzením příležitostí a vytvořením strategie šité na míru, která bude mít skutečný obchodní dopad. Kompletně za vás vyřešíme také starosti související se zaváděním regulace AI Act.
Služby datového inženýrství
Co kdybyste mohli mít nákladově efektivní, škálovatelná řešení, která rostou s vaším podnikáním? Specializujeme se na podnikové datové platformy, optimalizaci cloudové infrastruktury a posílení schopností datového inženýrství.
Naším cílem je viditelný dopad AI na váš byznys
V čem je spolupráce s BigHub jedinečná?
Business-first přístup

Data a AI jako software
Dlouhodobé partnerství
AI řešení dodáváme klientům napříč obory
Podívejte se, které konkrétní problémy pomáháme řešit klientům z různých odvětvích.
Odhalování podvodů v logistice
Zamezení krádežím elektřiny

Přesnější predikce poptávky
AI, která bezpečně a úspěšně mění celý provoz
Zlepšení diagnostiky pacientů

AI pro chytřejší a efektivnější výrobu
Předvídejte budoucí vývoj
Cenotvorba reagující na reálnou poptávku
Efektivnější a edukovanější zákaznická péče

Rychlejší proces likvidace a konzistentní evaluace

Plaťte jen reálnou spotřebu
Generativní AI, které můžete důvěřovat
Co si klienti cení o BigHubu
Přečtěte si hodnocení od našich důvěryhodných obchodních partnerů.

"AI asistent byl od samého začátku budován na silné spolupráci a důvěře. I bez předchozích zkušeností jsem se díky podpoře a vedení týmu BigHub dokázala rychle zorientovat. Výsledkem je řešení, které bylo kolegy velmi pozitivně přijato – aktuálně máme přes 800 aktivních uživatelů."

„Co dříve zabralo 10 minut hledání, dnes trvá jen 10 sekund. Když jsme s týmem před dvěma lety začínali, věděli jsme, že to nebude jednoduché. Ale teď, když vidím PROKOOP v akci, slyším pozitivní zpětnou vazbu a držím v ruce ocenění VIG XELERATE, vím, že to za to stálo.“

"Zákaznická zpětná vazba na automatizované zpracování škod je velmi pozitivní. Výrazné zrychlení vyřízení, zjednodušená komunikace a schopnost systému samostatně rozhodnout o výplatě do několika minut, zlepšuje celkový zákaznický dojem."


„Pro implementaci procesů řízených AI v naší e-commerce platformě jsme hledali partnera, který by mohl kombinovat inovace s praktickou aplikací. V BigHub jsme našli tým podporovaný předními experty v oblasti AI, který dokonale rozumí nejnovějším technologiím a dokáže je transformovat do funkčního řešení, které skutečně povýší náš on-line prodej a zákaznickou zkušenost na další úroveň.“


"S Bighubem se nezdržujeme u obecných sales prezentací, ale jdeme rovnou k věci – k use casům. Díky dostatečné hloubce detailu jsme schopni vést praktické workshopy s business týmy, kde společně identifikujeme příležitosti s nejvyšší návratností investice. Každý use case systematicky ho rozvíjíme, což nám umožňuje mezi nimi hledat synergie a posouvat využití AI v Sazce na vyšší úroveň."


"Na spolupráci s BigHub oceňuji jejich kombinaci technologické expertízy a praktického přístupu – mají opravdový tah na branku a chuť hledat řešení tam, kde jiní vidí překážky. Dokázali rychle reagovat na změny a vždy hledali cesty, jak projekt posunout dál. Těší mě, že jsme v BigHub našli partnera, který je spolehlivý a inspirativní.”

"Výsledky byly natolik přesvědčivé, že jsme je představili hlavním akcionářům, kteří schválili nasazení řešení BigHub do produkce. Současně jsme BigHub zapojili do tvorby datové strategie s cílem zpřístupnit klíčová data a lépe porozumět klíčovým oblastem byznysu. BigHub jsme vybrali jako partnera pro implementaci Big Data platformy a aplikace pro údržbu plynárenské sítě."


"T-Mobile usiloval o posílení svých AI schopností, aby zvýšil svou konkurenční výhodu. Oceňujeme odbornost týmu BigHub, který nás provedl celým rozhodovacím a implementačním procesem – od výběru a pořízení až po konfiguraci a využití analytické platformy s GPU akcelerací. Zároveň si velmi ceníme propojení hlubokých znalostí v oblasti strojového učení a platformového inženýrství při dodávkách reálných business řešení."


"Analytický nástroj od BigHub nám pomohl efektivně odhalit podezřelé odběry elektřiny. Navíc sloučením dosud oddělených datových zdrojů na jedno místo jsme získali možnost data dále analyzovat a pracovat na behaviorální segmentaci našich zákazníků."


"Na spolupráci s BigHub nejvíce oceňuji jejich schopnost propojit špičkové AI know-how s praktickými potřebami byznysu. BigHub není pouze technologická firma, ale taky skutečný partner. Tým dokázal rychle reagovat na změny, iterovat nad řešením a soustředit se na dosažení měřitelné hodnoty. V rychle se rozvíjející oblasti AI považuji jejich agilitu, produktové myšlení a orientaci na výsledky za významnou konkurenční výhodu."


"S projektem Datového bagru jsme velmi spokojeni a spolupráci hodnotíme jako přínosnou jak pro náš tým, tak pro výsledky projektu. BigHub vnímáme jako skutečného experta, který přináší funkční a promyšlená řešení. Velmi oceňujeme rychlost, flexibilitu a profesionální přístup v průběhu celé spolupráce."


„Spolupracujeme s BigHub na projektu inteligentního vyhledávání a od samého začátku nás nadchnul jejich zápal, odborné znalosti a vynikající proklientský přístup. Nejvíce si ceníme proaktivity a agilního myšlení.“


„Spolupráce s BigHub byla naprosto profesionální. Jasná komunikace a dobře definovaný rozsah od samého začátku zajistily efektivní průběh zakázky. Součástí byla i cenná výměna znalostí v oblasti strojového učení a umělé inteligence. Lidé z BigHub dodali přesně to, co slíbili, navíc včas a v rámci rozpočtu."


„BigHub považujeme za jednoho z předních poskytovatelů AI a datových řešení v Česku, což pravidelně dokazují prostřednictvím projektů, které spolu realizujeme. Nejenže nám pomáhají tyto projekty dodávat, ale také je s námi spoluvytvářejí a proaktivně hledají příležitosti, jak přinést hodnotu našemu byznysu.“
.avif)

"Považujeme BigHub za jednoho z předních dodavatelů AI a datových řešení v Česku, což opakovaně potvrzují projekty, na kterých společně pracujeme. Nejenže nám pomáhají tyto projekty realizovat, ale také se na jejich tvorbě aktivně podílejí a proaktivně vyhledávají příležitosti, jak přinášet obchodní hodnotu."

Takto díky AI posouváme firmy napříč různými obory kupředu
Výsledky jsou víc než slova. Přečtěte si, jak a s čím jsme pomohli konkrétním klientům.

Datart nasadil AI asistenta, který zvyšuje konverze a spokojenost zákazníků

Agentní systém zkrátil zpracování pojistné události z 15 na 2 minuty v Direct pojišťovně

Jak AI vyhledávání pomohlo AAA Auto zvýšit zapojení o 5 % a zjednodušit navigaci v mobilu

AI asistent PROKOOP pomáhá prodejnímu týmu Kooperativa snížit administrativu a více se zaměřit na klienty

AI řešení šetřící firmě Fortuna 94 % nákladů a tisíce hodin práce

Jak AI asistent DIEGO zrychlil provoz ve více než 100+ prodejnách PLANEO

AI řešení ve VR 3x zrychluje rozvoj prezentačních dovedností v ČPP

Ze 3 dnů na 30 minut: Jak NN pojišťovna zefektivnila likvidaci pojistných událostí
Partneři a certifikace
S využitím těchto partnerů, technologií a certifikací umožňujeme firmám přeměnit data na konkurenční výhodu.



Jsme hrdí na náš příběh oceněný veřejností
Co o BigHub píší média a kdo o nás mluví.


„Český BigHub se nebojí velkých dat ani velkých výzev.“
Firma BigHub, založená v roce 2016, se specializuje na špičkové datové technologie a pomáhá inovovat firmy napříč odvětvími.

„ČEZ spojil síly s BigHub, aby využil sílu umělé inteligence“
BigHub vznikl ve chvíli, kdy velké firmy neuměly efektivně využít AI. Dnes patří k nejrychleji rostoucím firmám v regionu.



Napište si o nezávaznou konzultaci zdarma
Chcete s námi probrat podrobnosti? Vyplňte krátký formulář níže a my se vám brzy ozveme, abychom si s vámi domluvili termín nezávazné online konzultace zdarma.
Novinky ze světa BigHub a umělé inteligence
Zjistěte a inspirujte se, co je nového v oblasti dat a umělé inteligence.

Proč AI coding nástroje a nové knihovny nemají běžet přímo na vašem Macu
Když se dnes řeší bezpečnost kolem vibe coding toolů, často to zní, jako by šlo o úplně nový problém. Ve skutečnosti nejde o nic nového. Jen jsme si poslední roky zvykli spouštět cizí kód, cizí dependencies a čím dál častěji i cizí shell commandy přímo na svém lokálním stroji, kde máme SSH klíče, .env soubory, přihlášený browser, přístupy do cloudu a často i produkci.
AI tooling ten problém nevymyslel. Jen ho dost zesílil a udělal viditelnější.
Na macOS je to podle mě vidět asi nejlíp. Spousta lidí nechce vyvíjet v Dockeru, protože DX jde rychle dolů a kontejnery na Macu pořád nejsou bez overheadu. Takže reálný default je pořád stejný: všechno běží na host machine a doufá se, že se nic nestane.
Tohle funguje přesně do chvíle, než to nefunguje.
LiteLLM jen připomněl starý problém
24. března 2026 se na PyPI objevily kompromitované verze litellm 1.82.7 a 1.82.8. Nešlo o žádný exotický exploit. Stačilo udělat pip install a do prostředí se dostal škodlivý .pth soubor, který se spouštěl při startu Pythonu.
Ten pak sahal po věcech, které na vývojářském stroji typicky najde snadno:
- SSH klíče
- .env soubory
- cloud credentials
- další secrets a konfigurační soubory
Pak je odesílal na remote server.
Na tomhle incidentu je důležité hlavně to, jak banální ten attack path byl. Nepotřeboval rozbít Python, obejít kernel ani přesvědčit člověka, aby spustil něco extra. Stačilo, že vývojář udělal to, co dělá běžně každý den: nainstaloval si dependency.
Paradoxně se na celou věc přišlo rychleji i proto, že malware nebyl úplně dobře napsaný a na některých strojích odpálil fork bombu. Kdyby se držel při zemi a jen tiše exfiltroval data, je dost možné, že by to déle unikalo pozornosti.
Podle mě by tomuhle podlehla velká část běžných developerů, ne jen lidi, kteří experimentují s vibe codingem. Důvod je jednoduchý: málokdo má lokální Python prostředí opravdu izolované.
A ani JavaScript svět na tom nebyl líp
Tohle mimochodem není jen Python story.
30. a 31. března 2026 se kompromitoval i axios, jedna z nejpoužívanějších knihoven v JavaScript světě. Útočník převzal maintainer účet na npm a publikoval škodlivé verze axios@1.14.1 a axios@0.30.4.
Zajímavé je, že škodlivý payload nebyl přímo v samotném axiosu. Ty verze jen přidaly novou transitive dependency plain-crypto-js, která se spouštěla přes postinstall hook. Jinými slovy: i tady stačilo udělat obyčejný install a z dependency chainu se stal execution chain.
To je přesně důvod, proč mi přijde nebezpečné tvářit se, že supply-chain riziko je jen problém nějakých pochybných balíčků z okraje ekosystému. Není. Minulý týden se to ukázalo i v jednom z nejběžnějších HTTP clientů pro Node.js.
exclude-newer je rozumný default
Jeden z mála levných guardrailů, které dávají smysl skoro každému, je neinstalovat úplně čerstvé releasy balíčků.
V uv jde použít exclude-newer, takže si dependency resolution omezíte jen na balíčky publikované před zvoleným datem:
[tool.uv]
exclude-newer = "2026-03-24"
Tohle není magická obrana. Jen si tím kupujete čas. Když budete držet třeba 14denní odstup, je slušná šance, že se během té doby na kompromitovaný release přijde a někdo ho stáhne nebo alespoň rozjede warningy napříč komunitou.
Úplně stejná logika platí pro AI coding tools
Stejně jako nechcete bezmyšlenkovitě pouštět čerstvé dependencies na hostu, nechcete na hostu pouštět ani code generátor s plným přístupem ke všemu okolo.
Tohle není argument proti Codexu, Claude Code ani jakémukoliv jinému nástroji. Je to argument proti tomu, jak velký trust těm nástrojům dáváme by default.
Lehké sandboxy jsou dobrý začátek. Codex CLI na macOS historicky používal sandbox-exec a umí tím dost omezit, kam proces smí sáhnout. V Claude Code jde sandbox zapnout přes /sandbox. V obou případech je to výrazně lepší než režim, kde agent vidí celý disk a může bez omezení pouštět shell.
Tohle má dvě praktické výhody:
- agent typicky vidí jen repozitář nebo explicitně povolené cesty
- nemusíte potvrzovat každou drobnost jen proto, abyste měli aspoň nějaký control surface
Pro běžné čtení, editaci souborů a část shell práce je to fakt příjemný middle ground.
Kde tenhle model naráží
Problém je, že lehký sandbox není totéž co skutečná izolace.
Jakmile nástroj potřebuje dělat něco trochu praktičtějšího, začnou vylézat hrany:
- instalace balíčků přes uv, pip, npm nebo podobné nástroje často sahá do globálních cache
- browser tooling nemusí uvnitř sandboxu fungovat dobře nebo vůbec
- některé MCP servery potřebují přístup mimo boundary repa
- dřív nebo později narazíte na command, který prostě musíte pustit mimo sandbox
A v ten moment se stejně vyhodí otázka na vibecodera jestli může systém sandbox odejít a většina klikne prostě na "Yes".
Proto mi přijde důležité neplést si "má nějaký sandbox mode" s "je to bezpečně izolované".
Co podle mě dává smysl víc
Pokud chceme agenty nebo code generátory používat vážně, potřebujeme reálný sandbox. Ideálně separátní VM nebo microVM pro každý projekt. Na Macu to může být něco ve stylu Lima nebo obdobné VM-based řešení. Docker sandboxy jsou v principu podobný směr, i když na macOS často naráží na performance a DX.
Pointa ale není konkrétní produkt. Pointa je trust boundary.
Do takového prostředí přesunete jen to, co ten konkrétní projekt opravdu potřebuje:
- checkout repa
- project-scoped credentials
- lokální cache jen pro ten projekt
- případně browser session nebo MCP servery, ale zase jen tam, kde to dává smysl
Tím snížíte blast radius hned dvakrát.
Za prvé: když agent spustí destruktivní command typu rm -rf /, tak zničí maximálně svůj sandbox.
Za druhé: když nainstalujete kompromitovanou dependency typu infikovaného litellm, tak z ní neodtečou všechny credentials z celého laptopu, ale maximálně to, co jste do toho konkrétního prostředí dali. Ideálně jen dev secrets pro jeden projekt.
To pořád není příjemný incident. Ale je to o řád lepší incident.
Classifier je fajn, ale není to sandbox
Claude Code teď přidal i auto mode, kde nad citlivějšími akcemi běží další classifier. Ten vyhodnocuje transcript a jednotlivé tool calls, hlavně Bash commandy a další akce mimo repo, a snaží se blokovat věci jako data exfiltration, credential hunting nebo destruktivní zásahy mimo scope úkolu.
To je rozumný posun. Approval fatigue je reálná a ruční odklikávání všeho není moc udržitelný model.
Ale i tady je podle mě důležité držet si správné očekávání: classifier je guardrail, ne izolace.
Stejně tak to neřeší supply-chain problém. Pokud si uvnitř důvěryhodného prostředí nainstalujete škodlivý balíček, classifier nad Bash commandy vám nepomůže proti tomu, co ten balíček provede při importu nebo startu interpreteru.
Co bych z toho bral jako praktický default
Můj aktuální take je jednoduchý:
- nepouštět úplně čerstvé dependencies bez odstupu
- neprovozovat AI coding tools přímo na host machine s plným přístupem
- když už používám lehký sandbox, nebrat ho jako finální řešení
- pro důležitější práci mít per-project izolované prostředí s omezeným blast radiusem
Tohle všechno platilo už dávno předtím, než někdo vymyslel termín vibe coding.
Jen teď už není moc kam uhýbat. Když dáte agentovi shell, filesystem, browser a credentials, dáváte mu v praxi velmi silné pravomoci. A jak ukázal LiteLLM incident, podobně silné pravomoci dostává i obyčejný package manager ve chvíli, kdy mu bez izolace dovolíte instalovat cizí kód přímo na svůj laptop.
To není niche security debata. To je docela obyčejný engineering default, který jsme měli mít už dávno.
Apple právě pracuje na novém container enginu který tohle všechno bude mít doufám built in. Do té doby se snažím opravdu koukat kdykoliv se spouští příkazy mimo sandbox.
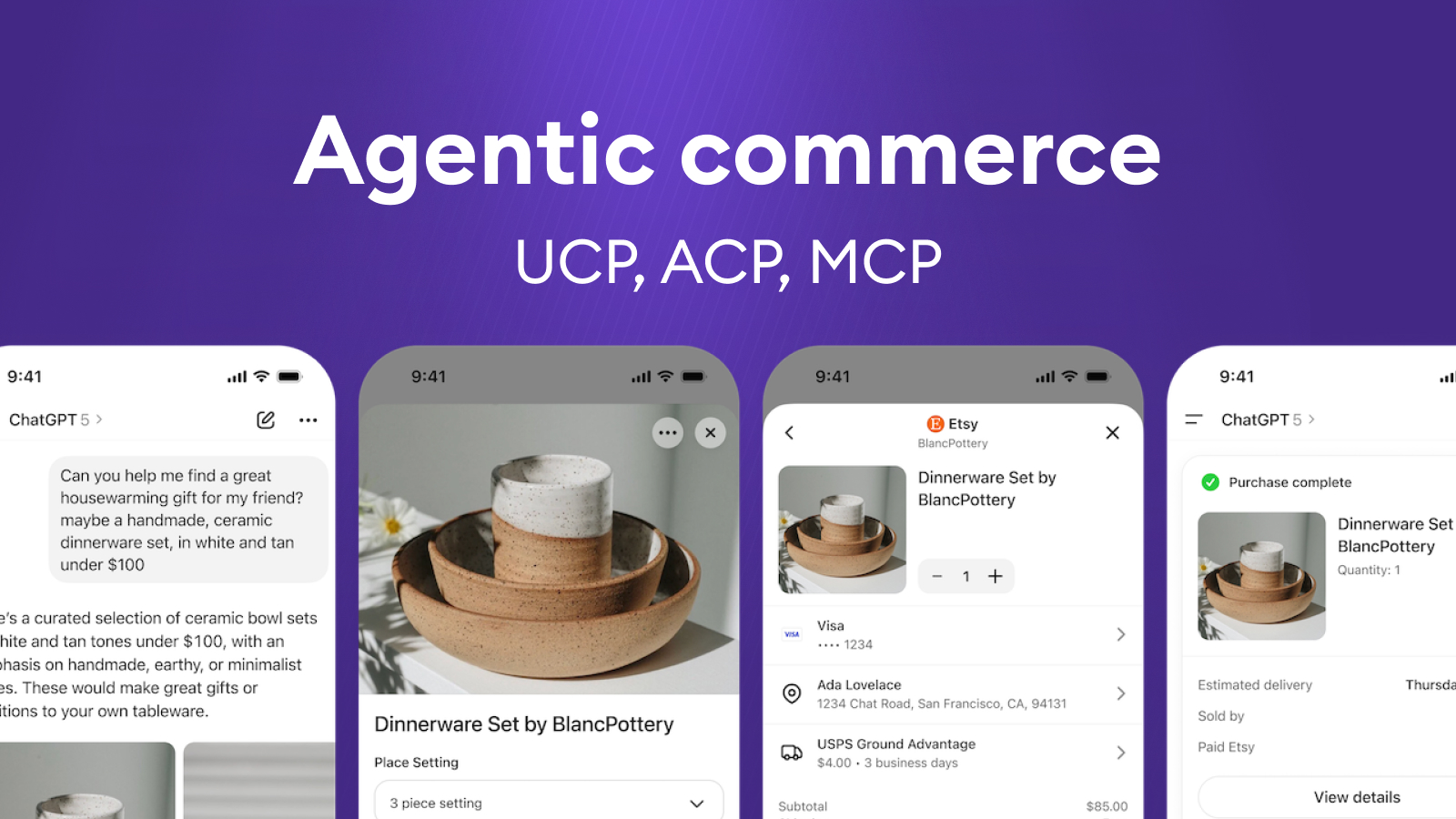
UCP, ACP, MCP v agentic commerce: AI už jen nedoporučuje, ale opravdu nakupuje
Současná situace
Za posledních pár měsíců se v oblasti AI a e-commerce objevilo několik zásadních novinek:
- Google představil UCP (Universal Commerce Protocol) – otevřený standard pro „agentic commerce“, který sjednocuje, jak AI agent mluví s merchantem: katalog, košík, doprava, platba, objednávka.
- OpenAI a Stripe dříve uvedli ACP (Agentic Commerce Protocol) – standard pro agentní checkout v ekosystému ChatGPT.
- Současně se rozšířil MCP (Model Context Protocol) jako obecný standard pro volání nástrojů a služeb a OpenAI Apps SDK jako produktová/distribuční vrstva pro agentní aplikace.
Jinými slovy: internet si začíná definovat standardizované „koleje“, po kterých budou AI agenti nakupovat. A trh se posouvá od režimu „AI něco doporučí“ k režimu „AI nákup skutečně provede“.
V článku probereme:
- co znamená agentic commerce v praxi,
- jak spolu souvisí UCP, MCP, Apps SDK a ACP,
- co tyto protokoly řeší – a co naopak neřeší,
- a kde dává smysl custom agentic commerce – přesně typ práce, které se věnujeme v BigHub.
Co je agentic commerce
Agentic commerce je forma digitálního obchodování, kdy autonomní AI agent obslouží část nebo celý nákupní proces za člověka či firmu – od hledání přes porovnávání až po zaplacení.
Typický scénář:
„Najdi mi běžecké boty na maraton do 3 000 Kč, které mi stihnou přijít do dvou týdnů.“
Agent poté:
- pochopí zadání,
- projde nabídky více obchodníků,
- porovná parametry, recenze, cenu a dopravu,
- připraví shortlist,
- po schválení uživatelem nákup dokončí – ideálně bez toho, aby člověk musel řešit klasický webový košík.
Podobné scénáře se netýkají jen B2C. Stejný princip lze použít pro:
- interní nákup materiálu,
- B2B objednávky,
- opakované doplňování zásob,
- servisní a reklamační procesy.
Směr je jasný: AI se posouvá z roviny „pomoz mi vybrat“ do roviny „postarej se o to“.
MCP, Apps SDK, UCP, ACP
MCP – obecný standard pro nástroje a capabilities
MCP (Model Context Protocol) je:
- obecný standard pro to, jak agent volá nástroje, API a služby,
- doménově neutrální vrstva („umím mluvit s CRM, pricingem, katalogem, ERP…“),
- způsob, jak agent „vidí“ svět skrz capabilities, které má k dispozici.
Zjednodušeně: MCP = jak agent sahá do vašich systémů.
OpenAI Apps SDK – produktová a distribuční vrstva
OpenAI Apps SDK:
- řeší UI, runtime a distribuci agentů (ChatGPT Apps, rozhraní pro uživatele),
- umožňuje rychle zabalit agenta do produktu:
- chat, formuláře, akce,
- publikace do ekosystému ChatGPT,
- základní správu a běh.
Zjednodušeně: Apps SDK = jak z agenta udělat reálně používaný produkt.
UCP – doménový standard pro commerce workflow
UCP (Universal Commerce Protocol) od Google a partnerů:
- je doménový standard pro commerce,
- sjednocuje, jak agent mluví s merchantem o:
- katalogu, variantách a cenách,
- košíku, dopravě, platbě, objednávce,
- slevách, věrnostních programech, refundech a trackingu,
- je navržený tak, aby fungoval napříč Google Search, Gemini a dalšími AI surfaces.
Zjednodušeně: UCP = konkrétní jazyk a workflow nákupu.
ACP – standard pro agentní checkout v ChatGPT
ACP (Agentic Commerce Protocol) od OpenAI/Stripe:
- řeší podobnou doménu z pohledu ChatGPT ekosystému,
- soustředí se silně na checkout, platby a objednávku,
- stojí za funkcemi typu Instant Checkout v ChatGPT.
Z pohledu obchodníka jsou UCP a ACP konkurenční commerce standardy (nikdo nechce tři různé integrace).
Z pohledu architektury jde ale o možné „dialekty“, které může agent používat podle kanálu, odkud přichází (ChatGPT vs. Google / Gemini).
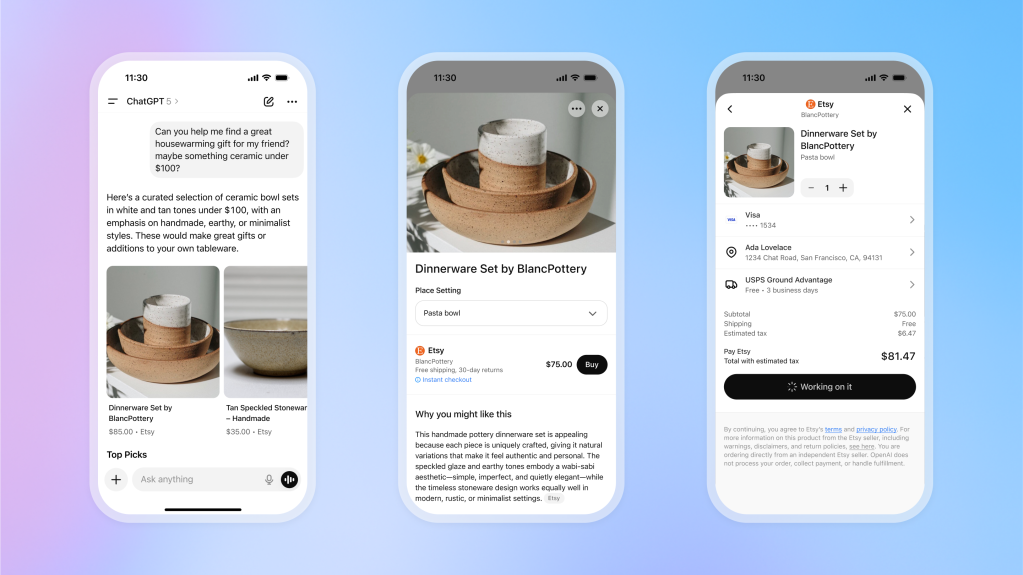
Co tyto standardy řeší – a co ne
Společné je jedno - UCP ani ACP z agenta neudělají „mozek“. Jen mu dají jednotný jazyk.
Standardy typicky řeší:
- jak agent formálně komunikuje s merchantem a checkoutem,
- jak strukturovaně vypadají nabídky a objednávky,
- jak bezpečně probíhá platba a autorizace,
- jak se dá nákup zpracovat napříč různými AI kanály.
Neřeší (a ani nemůžou řešit):
- kvalitu a strukturu produktového katalogu, atributů a dostupnosti,
- integraci do ERP, WMS/OMS, CRM, věrnostního systému, pricing enginu, kampaní,
- business logiku – marže vs. SLA vs. zákaznická zkušenost vs. obrat,
- governance, risk, schvalování – kdo má právo co objednat, kdy musí zasáhnout člověk, jak se auditují rozhodnutí.
Prakticky to znamená:
- můžete být formálně „UCP/ACP ready“,
- ale agentická zkušenost bude pořád špatná, pokud:
- data jsou nekonzistentní,
- doručovací sliby se nedají splnit,
- pricing a promo logika nedrží v multi-channel světě pohromadě,
- agent nemá přístup k reálným stavům a interním pravidlům.
Standard je nutné technické minimum, ne hotové řešení.
Jak k agentic commerce přistupujeme v BigHub
V BigHub vnímáme UCP, MCP, ACP a Apps SDK jako stavební bloky infrastruktury. Na projektech se soustředíme na to, co nad nimi vytvoří skutečnou konkurenční výhodu.
Stavíme ML-powered commerce agenty, kteří umí:
- dynamické nabídky a cenotvorbu (bundly, alternativy, chytré trade-offy podle marže, SLA a priorit),
- personalizované vyhledávání a shortlist (kontext zákazníka, preference, rozpočet, historie interakcí),
- argumentaci a práci s námitkami (proč právě tahle varianta, srovnání možností, vysvětlení trade-offů),
- a v neposlední řadě hladký checkout, přes platbu a finální nákup.
Nad tím stavíme integrační vrstvu přes MCP (capabilities + napojení na core systémy). Jako UI a distribuční vrstvu často používáme OpenAI Apps SDK, když potřebujeme rychle dostat agenta k reálným uživatelům. Tam, kde to dává smysl, využíváme standardy jako UCP/ACP, místo abychom psali proprietární integrace pro každý kanál zvlášť.
Kde dává smysl custom agentic commerce
Standardy (UCP/ACP/MCP) mají velkou hodnotu tam, kde:
- nechcete vymýšlet vlastní protokol pro napojení na AI kanály,
- potřebujete interoperabilitu (ChatGPT, Google/Gemini, další),
- chcete snížit integrační zátěž na straně merchantů.
Custom přístup dává největší smysl v těchto oblastech:
1) Propojení agenta s core systémy
- ERP, WMS/OMS, CRM, věrnostní programy, pricing engine, reklamace, call centrum…
- agent musí žít v reálné provozní architektuře, ne v izolovaném sandboxu.
Typicky je potřeba vlastní integrační a orchestrace vrstva, která:
- „nahoru“ mluví UCP/ACP/MCP,
- „dolů“ mluví vašimi konkrétními systémy a API.
2) Doménová logika a business pravidla
Tady vzniká skutečná konkurenční výhoda:
- kdy může agent objednat autonomně a kdy má jen doporučovat,
- jak balancuje marži, SLA, dostupnost, zákaznickou zkušenost a obrat,
- jak zachází s akcemi, věrnostními body, cross-sell / up-sell scénáři.
Tohle už není otázka protokolu, ale konkrétních pravidel nad daty a KPI vaší firmy.
3) Multi-kanál a mix B2C / B2B / interních agentů
Reálný svět vypadá takto:
- B2C e-shop,
- B2B portál,
- interní agent pro nákup,
- prodejní asistent na prodejně,
- agent v zákaznické péči.
Custom framework umožní:
- sdílet logiku napříč rolemi a kanály,
- pracovat s oprávněními a limity,
- řešit scénáře typu „AI začne v chatu, dokončí na pobočce“.
4) Evropský kontext: regulace, bezpečnost, data residency
U evropských firem hraje velkou roli:
- regulace (EU AI Act, GDPR, sektorová regulace),
- bezpečnostní politika, interní audity,
- kde běží data a modely (US vs. EU),
- jak vysvětlitelná a auditovatelná jsou rozhodnutí agenta.
Standardy jsou globální, ale architektura a governance musí být lokální a na míru.
Co si z UCP a spol. odnést jako retailer / enterprise
Pokud přemýšlíte o agentic commerce, stojí za to položit si několik praktických otázek:
- Jsme „agent-ready“ nejen na úrovni protokolu, ale i dat a procesů?
- Ve kterých use-casech chceme, aby agent nákup opravdu provedl, a kde má zůstat jen u doporučení?
- Jak agentic commerce zapadne do našich stávajících systémů, pricingu, kampaní a SLA?
- Kdo u nás vlastní agentní iniciativy (KPI, P&L) a jak je budeme měřit?
- Které části dává smysl řešit přes standardy (UCP/ACP/MCP) a kde už potřebujeme vlastní agentní framework?
Jak vytvořit inteligentní vyhledávání: Od fulltextu k hybridnímu vyhledávání s optimalizací
Problém: Limity tradičního vyhledávání
Tradiční fulltextové vyhledávání, založené na algoritmech jako BM25, má několik zásadních omezení:
1. Překlepy a variace
- Uživatelé často píší dotazy s překlepy nebo používají různé varianty názvů
- Tradiční vyhledávání vyžaduje přesnou shodu nebo velmi podobný text
2. Vyhledávání pouze v názvech
- Fulltextové vyhledávání typicky hledá pouze v konkrétních polích (například název produktu nebo entity)
- Pokud je relevantní informace v popisu nebo v souvisejících entitách, systém ji nenajde
3. Chybějící sémantické porozumění
- Systém nerozpozná synonyma nebo související koncepty
- Například dotaz "auto" nenajde výsledky obsahující "automobil" nebo "vůz", i když jde o stejný koncept
- Mezijazyčné vyhledávání je téměř nemožné – český dotaz nenajde anglické výsledky
4. Kontextové vyhledávání
- Uživatelé často hledají podle kontextu, ne přesných názvů
- Například dotaz "produkty od výrobce X" by měl najít všechny relevantní produkty, i když název výrobce není explicitně uveden v dotazu
Řešení: Hybridní vyhledávání s embeddingy
Řešením je kombinace dvou přístupů: tradičního fulltextového vyhledávání (BM25) a vektorových embeddingů pro sémantické vyhledávání.
Vektorové embeddingy pro sémantické porozumění
Vektorové embeddingy převádějí text do vícerozměrného prostoru, kde podobné významy jsou blízko sebe. To umožňuje:
- Vyhledávání podle významu: Dotaz "notebook" najde výsledky obsahující "laptop", "přenosný počítač" nebo dokonce související koncepty
- Mezijazyčné vyhledávání: Český dotaz může najít anglické výsledky, pokud mají podobný význam
- Kontextové vyhledávání: Systém rozumí vztahům mezi entitami a koncepty
- Vyhledávání v celém obsahu: Embeddingy mohou být vytvořeny z celého dokumentu, nejen z názvu
Proč embeddingy samotné nestačí
I když jsou embeddingy mocným nástrojem, samy o sobě nejsou dostatečné:
- Překlepy: Vektorové embeddingy mohou mít problém s překlepy, protože malá změna v textu může vést k odlišnému embeddingu
- Přesné shody: Někdy chceme najít přesnou shodu názvu, což fulltextové vyhledávání dělá lépe
- Výkon: Vektorové vyhledávání může být pomalejší než optimalizované fulltextové indexy
Hybridní přístup: BM25 + HNSW
Ideální řešení kombinuje oba přístupy:
- BM25 (Best Matching 25): Tradiční fulltextový algoritmus, který exceluje v přesných shodách a zpracování překlepů
- HNSW (Hierarchical Navigable Small World): Efektivní algoritmus pro vyhledávání v prostoru vektorů, který umožňuje rychlé nalezení nejbližších sousedů v embedding prostoru
Kombinací těchto dvou přístupů získáme to nejlepší z obou světů: přesnost fulltextového vyhledávání pro přesné shody a sémantické porozumění embeddingů pro kontextové dotazy.
Výzva: Správné seřazení výsledků
Najít relevantní výsledky je jen první krok. Stejně důležité je je správně seřadit. Uživatelé typicky klikají na první několik výsledků, takže špatné seřazení může výrazně snížit užitečnost vyhledávání.
Proč samotné seřazení (sort by) nestačí
Jednoduché seřazení podle jednoho kritéria (například data) není dostatečné, protože potřebujeme zohlednit více faktorů současně:
- Relevance: Jak dobře výsledek odpovídá dotazu (z fulltextového i vektorového vyhledávání)
- Obchodní hodnota: Výsledky s vyšší marží by měly být výše
- Čerstvost: Novější položky jsou často relevantnější než staré
- Popularita: Populárnější položky mohou být pro uživatele zajímavější
Scoring funkce: Kombinace více faktorů
Místo jednoduchého "sort by" potřebujeme komplexní scoring systém, který kombinuje:
- Fulltextové skóre: Jak dobře výsledek odpovídá dotazu podle BM25
- Vektorové distance: Sémantická podobnost podle embeddingů
- Scoring funkce:
- Magnitude funkce pro marži/popularitu (vyšší hodnoty = vyšší skóre)
- Freshness funkce pro čas (novější = vyšší skóre)
- Další obchodní metriky podle potřeby
Výsledné skóre je pak vážená kombinace všech těchto faktorů. Problém je, že správné váhy nejsou zřejmé a musíme je najít experimentálně.
Hyperparameter search: Hledání optimálních vah
Správné nastavení vah pro fulltextové vyhledávání, vektorové embeddingy a scoring funkce je kritické pro kvalitu výsledků. Tento proces se nazývá hyperparameter search.
Vytvoření testovacího datasetu
Základem úspěšného hyperparameter search je kvalitní testovací dataset. Vytvoříme dataset dotazů, u kterých přesně víme, jak by měly vypadat ideální výsledky:
- Referenční výsledky: Pro každý testovací dotaz máme seznam očekávaných výsledků v správném pořadí
- Anotace: Každý výsledek je označen jako relevantní nebo nerelevantní, případně s prioritou
- Reprezentativní vzorky: Dataset by měl pokrývat různé typy dotazů (přesné shody, synonyma, překlepy, kontextové dotazy)
Metriky pro hodnocení kvality
Abychom mohli objektivně posoudit, zda jsou výsledky dobré, potřebujeme metriky, které porovnávají skutečné výsledky s referenčními:
1. Kontrola úplnosti (Recall)
- Obsahují výsledky vše, co by měly obsahovat?
- Jsou všechny relevantní položky přítomny v seznamu výsledků?
2. Kontrola pořadí (Ranking Quality)
- Jsou výsledky ve správném pořadí?
- Jsou nejrelevantnější výsledky na prvních místech?
Mezi konkrétní metriky patří například NDCG (Normalized Discounted Cumulative Gain), která hodnotí jak úplnost, tak správné pořadí výsledků. Další užitečné metriky zahrnují Precision@K (kolik relevantních výsledků je v prvních K pozicích) nebo MRR (Mean Reciprocal Rank), která měří pozici prvního relevantního výsledku.
Iterativní optimalizace
Proces hyperparameter search probíhá iterativně:
- Nastavení počátečních vah: Začneme s rozumnými výchozími hodnotami
- Testování kombinací: Systematicky testujeme různé kombinace vah pro:
- Váhy fulltextových polí (například název produktu vs. popis)
- Váhy vektorových polí (embeddingy pro různé části dokumentu)
- Boost hodnoty pro scoring funkce (marže, čas, popularita)
- Agregační funkce (jak kombinovat různé scoring funkce)
- Hodnocení výsledků: Pro každou kombinaci spustíme vyhledávání na testovacím datasetu a vypočítáme metriky
- Výběr nejlepších parametrů: Vybereme kombinaci s nejlepšími metrikami
- Refinování: Pokud je to potřeba, zúžíme rozsah testování kolem nejlepších hodnot a opakujeme proces
Tento proces může být časově náročný, ale je nezbytný pro dosažení optimálních výsledků. Automatizace tohoto procesu umožňuje testovat stovky nebo tisíce kombinací parametrů a najít ty nejlepší.
Sledování a iterativní zlepšování
I po optimalizaci parametrů je důležité systém kontinuálně sledovat a zlepšovat.
Sledování chování uživatelů
Klíčovou metrikou je, zda uživatelé klikají na výsledky, které jim systém nabízí. Pokud uživatel neklikne na první výsledek, ale až na třetí nebo čtvrtý, je to signál, že seřazení není optimální.
Co sledovat:
- Click-through rate (CTR): Kolik uživatelů klikne na výsledky
- Pozice kliknutí: Na které pozici uživatelé klikají (ideálně by měli klikat na první výsledky)
- Dotazy bez kliknutí: Dotazy, na které uživatelé vůbec nekliknou, mohou indikovat špatné výsledky
Analýza problémových případů
Když identifikujeme dotazy, kde uživatelé neklikají na první výsledky, měli bychom:
- Zaznamenat tyto případy: Uložit dotaz, vrácené výsledky a pozici, na kterou uživatel klikl
- Analyzovat: Proč systém vrátil špatné pořadí? Chybí relevantní výsledky? Jsou na špatných pozicích?
- Přidat do testovacího datasetu: Tyto případy by měly být součástí našeho testovacího datasetu pro budoucí optimalizace
- Upravit váhy: Na základě analýzy můžeme upravit váhy nebo přidat nová pravidla
Tento iterativní proces zajišťuje, že systém se neustále zlepšuje a přizpůsobuje se skutečnému chování uživatelů.
Implementace na Azure: AI Search a OpenAI Embeddings
Všechny tyto komponenty můžeme efektivně implementovat pomocí služeb Microsoft Azure.
Azure AI Search
Azure AI Search (dříve Azure Cognitive Search) poskytuje:
- Hybridní vyhledávání: Nativní podpora pro kombinaci fulltextového (BM25) a vektorového vyhledávání
- HNSW indexy: Efektivní implementace HNSW algoritmu pro vektorové vyhledávání
- Scoring profiles: Flexibilní systém pro definování vlastních scoring funkcí
- Text weights: Možnost nastavit váhy pro různá fulltextová pole
- Vector weights: Možnost nastavit váhy pro různá vektorová pole
Azure AI Search umožňuje definovat scoring profiles, které kombinují:
- Magnitude scoring funkce pro numerické hodnoty (marže, popularita)
- Freshness scoring funkce pro časové hodnoty (datum vytvoření, datum aktualizace)
- Text weights pro fulltextová pole
- Vector weights pro vektorová pole
- Agregační funkce pro kombinování různých scoring funkcí
OpenAI Embeddings
Pro vytváření embeddingů používáme OpenAI Embeddings, konkrétně modely jako text-embedding-3-large:
- Kvalitní embeddingy: OpenAI modely poskytují vysoce kvalitní embeddingy, které dobře fungují i pro češtinu
- Konzistentní API: Jednoduchá integrace s Azure AI Search
- Škálovatelnost: OpenAI API zvládne velké objemy požadavků
OpenAI embeddingy jsou zvlášť vhodné pro češtinu, protože byly trénovány na vícejazyčných datech a poskytují dobré výsledky i pro menší jazyky.
Integrace
Azure AI Search umožňuje přímo použít OpenAI embeddingy jako vectorizer, což zjednodušuje integraci. Můžeme definovat vektorová pole v indexu, která automaticky používají OpenAI pro vytváření embeddingů při indexování dokumentů.